Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
Example 1:
Input: [3,2,1,5,6,4] and k = 2
Output: 5
Example 2:
Input: [3,2,3,1,2,4,5,5,6] and k = 4
Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
Example 1:
Input: [3,2,1,5,6,4] and k = 2
Output: 5
Example 2:
Input: [3,2,3,1,2,4,5,5,6] and k = 4
对于有序数据的存储,常见的数据结构有:
Shuffle是下一个Stage向上一个Stage获取数据的过程,其中涉及到序列化、磁盘IO、网络IO等相对较慢的操作,所以减少和优化Shuffle过程有利于程序性能的提升。
MapReduce中的shuffle:
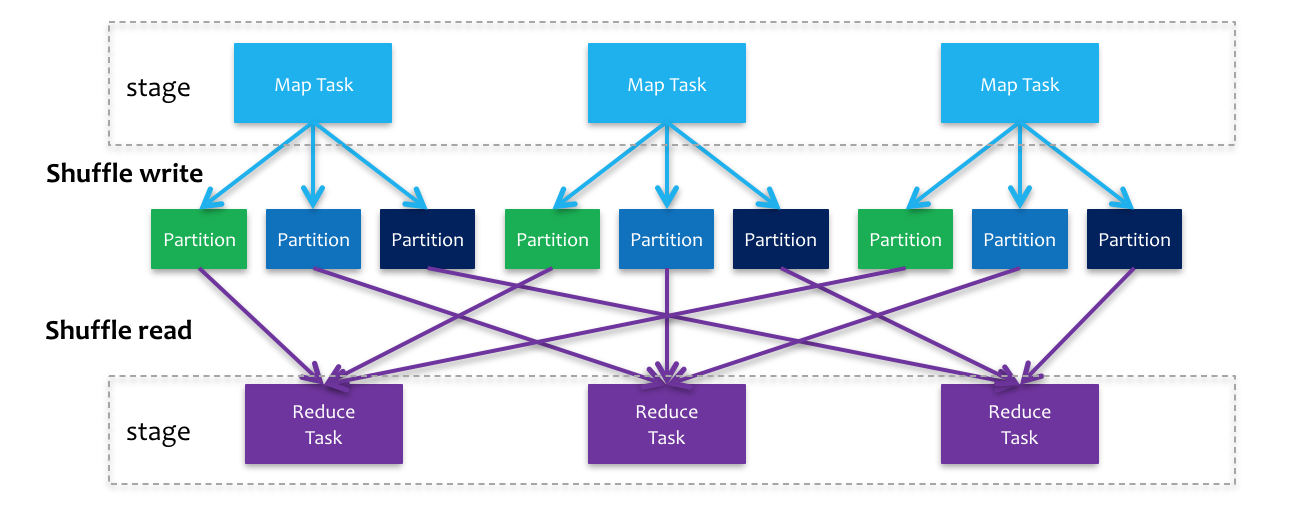
在Spark中Shuffle和MR中的类似,也分为Shuffle Read和Shuffle Write,而且shuffle write也是将结果写入到磁盘中。
Spark中对于Shuffle的管理由ShuffleManager完成,ShuffleManager也从开始的HashShuffleManager演变为现在常用的SortShuffleManager。
SparkSQL对于join的实现有3种:
Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
Example 1:
Input:nums = [1,1,1], k = 2
Output: 2
Note:
今天看到两道题:
equals和==有什么区别?
Integer a = 1;
Difficulty: Easy
Given a non-empty array of integers, every element appears twice except for one. Find that single one.
Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
Example 1:
Input: [2,2,1]
在spark开发过程中,广播变量会被分发到Executor,当Executor执行多个Task时会复用广播变量。所以广播变量最常见的使用场景有两个:
共享重资源:重资源的初始化十分消耗性能(例如:各类存储系统的客户端和连接池等),如果不使用广播可能造成频繁的初始化而影响性能,即使基于分区创建连接,在分区数较多的情况下也会占用大量资源。共享只读数据:多次使用的只读数据可以使用广播发送到每个节点,避免重复传输,起到性能优化的作用。
class StandardTests {
@BeforeAll
static void initAll() {
}