Shuffle是下一个Stage向上一个Stage获取数据的过程,其中涉及到序列化、磁盘IO、网络IO等相对较慢的操作,所以减少和优化Shuffle过程有利于程序性能的提升。
MapReduce中的shuffle:
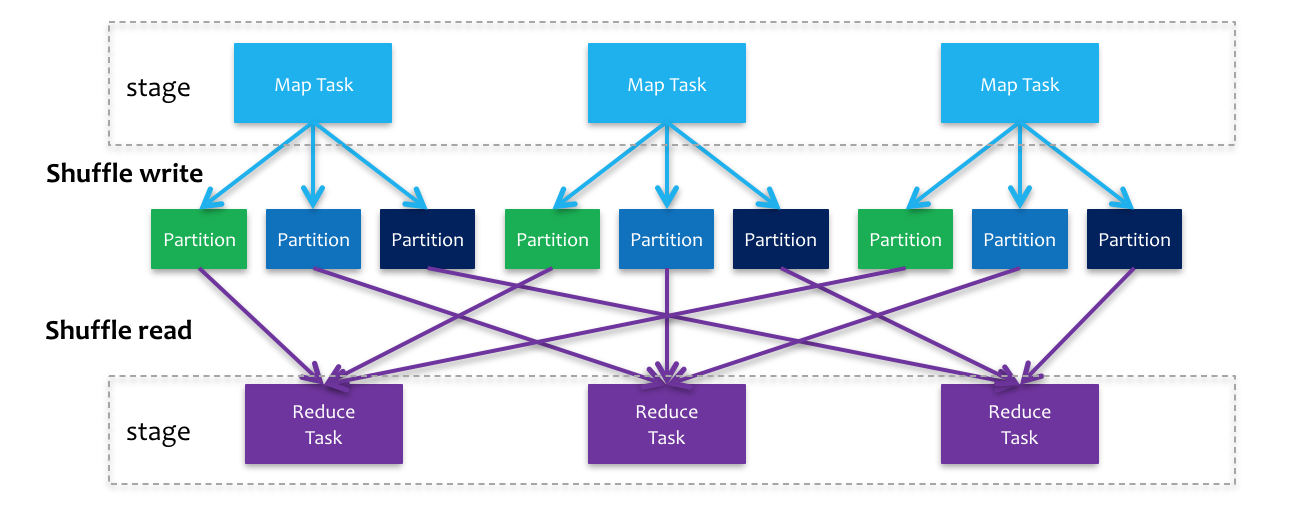
1. Spark Shuffle过程
在Spark中Shuffle和MR中的类似,也分为Shuffle Read和Shuffle Write,而且shuffle write也是将结果写入到磁盘中。
2. ShuffleManager
Spark中对于Shuffle的管理由ShuffleManager完成,ShuffleManager也从开始的HashShuffleManager演变为现在常用的SortShuffleManager。
2.1 HashShuffleManager
上游Stage会根据下游Stage的Task个数对数据进行hash分区后通过shuffle write写入对应的分区文件中,即:每个上游Task会针对每一个下游分区生成一个文件(如果存在该分区数据)。
这种方式可能会产生大量文件,所以HashShuffleManager有一个优化参数spark.shuffle.consolidateFiles=true,来缓解这一问题,原理很容易理解:shuffle write在写入文件时有buffer作为缓冲,此参数可以使同一Executor同一CPU core执行的Task复用此buffer,实现数据追加到老文件,避免创建新文件。
但是如果ReduceTask数量很多时还是会有很多文件产生,大量的文件会导致大量的句柄对象占用资源。
2.2 SortShuffleManager
SortShuffleManager的shuffle write是在内存中维护了一个数据结构(map或数组),当读入数据到达一定数量后按key进行排序然后写入临时文件和索引(起始值),当Task完成时将临时文件归并合并成一个文件,所以最终的文件数为Map Task的个数
bypass运行:当shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值或使用非聚合类的shuffle算子(比如reduceByKey)会触发。此过程和HashShuffleManager一致,但是会在最后将多个分区文件合并。
SortShuffleManager减少了文件个数,但是需要对数据进行排序会降低性能。
2.3 Tungsten-Sort Based Shuffle
为了进一步优化SortShuffleManager,Spark 1.6引入了Tungsten-Sort Based Shuffle,通过JAVA中的Unsafe API对序列化后的二进制数据指针排序,减少了GC和内存占用,提升了排序性能,但是此排序不能有aggregate操作且分区数小于2^24 - 1。